
 河北
河北
編輯|張倩
一個機器人到底需要多「聰明」,你才愿意把它請進家門?
前段時間,明星具身智能公司 1X 開始預售其人形機器人 Neo。演示視頻中,它能從冰箱取水、疊衣服、把餐具放進洗碗機,儼然一個稱職的家務助手。
但問題是,它當時真正能自主完成的,也只有這幾件事。至于更多樣的日常任務 —— 比如整理散落的玩具、擦拭臺面、收納雜物 —— 在現階段,大多仍需要工程師遠程教學。
這就多少有些令人遲疑:花費近 14 萬元,迎來的不僅是一個「助手」,還可能是一雙需要你授權進入家庭隱私空間的「眼睛」。社交網絡上,不少人也對這種「半成品智能」表達了困惑甚至調侃。



這種「演示場景自主、真實任務依賴人工」的割裂狀態,恰恰映射出當前具身智能落地的核心挑戰:泛化能力不足
要突破這一瓶頸,業界共識是:需要更大規模、更多樣化的真實機器人數據來「喂養」模型,使其學習到更本質的任務理解與動作泛化能力。然而,高質量真機數據的采集成本極高,且不同構型機器人的數據難以復用,導致大多數模型仍只能在有限數據或仿真環境中訓練,難以實現真正的跨任務、跨本體泛化。
在這一背景下,螞蟻靈波開源發布的第一款具身智能基座模型 LingBot-VLA帶來了一個好消息:它基于約 20000 小時、覆蓋 9 種主流雙臂機器人構型的真實世界數據預訓練而成,在涵蓋 100 多項任務的統一真機評測基準下整體表現超越 Pi0.5,成為了能夠跨本體、跨場景泛化的開源具身基座模型新標桿。
這一超越并非偶然,而是源于 LingBot-VLA 在模型架構、數據規模與訓練效率上的系統性突破。在最新的技術報告中,我們可以看到相關細節。而且,螞蟻靈波還開源了相應的模型權重、代碼、后訓練工具鏈,確保開發者不僅能拿到模型,還能把模型調得更好。

- 項目鏈接:https://technology.robbyant.com/lingbot-vla
- 技術報告鏈接:https://arxiv.org/pdf/2601.18692
- 模型下載鏈接:https://huggingface.co/collections/robbyant/lingbot-vla
- 代碼、后訓練工具鏈鏈接:https://github.com/robbyant/lingbot-vla
看來,在具身智能這個領域,通過大規模擴展真實數據驅動模型泛化,已從技術愿景走向工程現實。
超越 Pi0.5,意味著什么?
在 LingBot-VLA 出現之前,Physical Intelligence 開源的 Pi0.5 幾乎是行業內無法繞開的標桿。
為什么它有這么強的統治力?根本原因在于,Pi0.5 首次在開源世界里證明了:一個模型,不需要針對特定場景專門訓練,就能在完全陌生的真實家庭環境中,完成長達 10-15 分鐘的復雜操作鏈條。這件事讓行業第一次清晰地看到,具身智能并非只能在「擺拍式」的單一任務中工作,而是有可能真正進入非結構化、充滿不確定性的真實生活場景,完成從「實驗室奇觀」到「規模化產品」的過渡
所以無論是學術論文里的對比實驗,還是產業界的模型選型,Pi0.5 都是那個「必須要放進去比一比」的對象。也因為有這么一個「扛把子」的開源模型存在,很多機器人公司并不直接從零訓練模型,而是選擇在 Pi0.5 的基礎上進行微調,再部署到自己的機器人本體上,這也進一步鞏固了它在開源具身生態中的核心地位。
當然,也有不少團隊選擇正面硬剛,以自研模型對標 Pi0.5。但真正落到實際評測中,情況卻要復雜得多。許多模型往往只能在某一個特定任務、某一種固定構型的機器人上取得更好的成績,一旦換一個任務類型,或換一臺不同本體的機器人,優勢就會消失,甚至性能大幅退化。本質上,這仍然是專用模型在特定分布上的勝利,而不是泛化能力的提升。
這種局面很大程度上受制于底層的現實約束。我們知道,目前困擾具身模型的最大問題就是數據不夠用,而數據與特定硬件的強綁定又加劇了這一問題。如果模型和訓練范式無法高效吸收多源異構數據,那么簡單地「多喂數據」這條路就跑不通。
也正是在這樣的行業背景下,真正意義上的「整體超越 Pi0.5」,才顯得格外稀缺。它不只是某個指標上的領先,還意味著模型在數據利用方式、訓練效率以及跨本體、跨任務泛化能力上,已經邁過了一個新的臺階。LingBot-VLA 的出現,正是在這個時間點上,給出了一個不同于以往的答案。
三大平臺,100 項真機任務
LingBot-VLA 經住了考驗
LingBot-VLA 的強泛化能力,本質上來源于其對海量跨本體數據的有效利用。這個模型所用的 20000 小時真機數據,來自 9 個不同的機器人平臺。傳統上,由于不同機器人之間的傳感器、控制接口、本體結構差異巨大,這些數據是很難被統一利用的,而 LingBot-VLA 打破了這一瓶頸。

為了驗證 LingBot-VLA 到底有多強,螞蟻靈波在一個全新的具身智能基準 ——GM-100上對其進行了測試。
這個基準總共包含 100 項真機任務,由上海交大牽頭,螞蟻靈波等多機構聯合研發。我們打開它的官網看了一下,發現事情并不簡單 —— 那些任務不是簡單的「pick,hold,place(拿取,保持,放置)」操作,而是涉及了很多長序列任務和精細操作,比如串糖葫蘆、拉軟包拉鏈、疊衣服…… 一些看似簡單的任務,比如按臺燈開關、整理小物體,也會因為機械臂構型、物體材質、位置擺放、指令理解等因素而呈現出區分度。可以說,GM-100 通過精心設計復雜、長尾的多樣化任務,為具身大模型設置了一張科學、嚴謹且難以取巧的「統考卷」。想在這樣一個數據集上拿到好成績,對于現階段的模型來說是相當不容易的。

https://mp.weixin.qq.com/s/o0WKZi-JFYd8ZDHV6_5Xfg?click_id=26
即使是這樣,螞蟻靈波還是選擇繼續上難度 —— 模型并非僅在單一機器人上驗證,而是被部署在來自三大不同平臺(AgileX、Agibot G1、Galaxea R1Pro)的 25 臺機器人上統一執行任務。如此一來,整個測試就成了一個跨本體、跨任務能力的綜合考驗
同時參與測試的還有 GR00T、WALL-OSS 以及 Pi0.5,這些都是開源具身模型里的優秀代表。
實驗結果顯示,無論在哪個平臺上,LingBot-VLA 的成功率(SR)和部分成功率(PS,子步驟完成情況)都是最高的。尤其在融入基于深度的空間信息后,模型優勢更加明顯 —— 相比 Pi0.5 平均 SR 提高了 4.28%,PS 提高了 7.76%。這說明,無論是在復雜長序列任務的執行精度上,還是在面對新任務的適應能力上,LingBot-VLA 都展現出了更勝一籌的智能水平。


https://mp.weixin.qq.com/s/o0WKZi-JFYd8ZDHV6_5Xfg?click_id=26

https://mp.weixin.qq.com/s/o0WKZi-JFYd8ZDHV6_5Xfg?click_id=26
另外,值得注意的是,LingBot-VLA 的數據利用效率和算力效率也更高
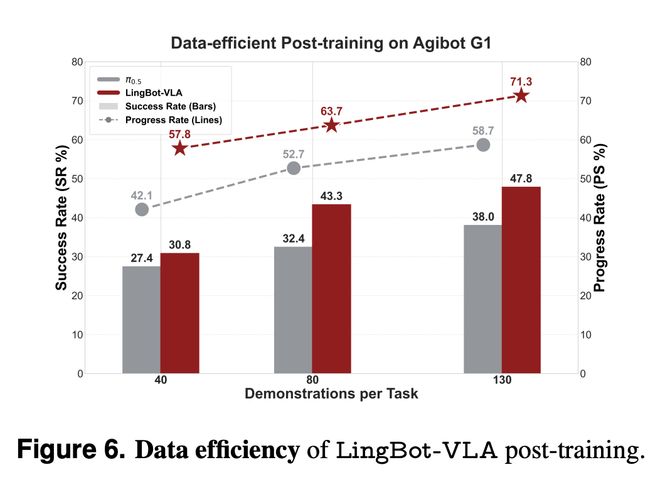
實驗顯示,在 Agibot G1 平臺上,僅使用 80 條示范數據進行后訓練,LingBot-VLA 的表現就超越了使用 130 條完整數據訓練的 Pi0.5 模型。而且,當數據量逐步增加時,LingBot-VLA 與 Pi0.5 的性能差距進一步拉大,這從側面印證了其模型架構在學習潛能和泛化可擴展性上的設計優勢。
而在算力效率方面,LingBot-VLA 的訓練框架也展現出明顯優勢。在相同數據集和標準化架構下,其訓練吞吐量(samples/s)均顯著高于 StarVLA、Dex Botic、OpenPI 等主流開源框架,在 Qwen2.5-VL-3B-π 與 PaliGemma-3B-pt-224-π 兩種模型設置下均實現最快訓練速度。更突出的是,隨著 GPU 規模從 8 卡擴展至 256 卡,其訓練效率仍能緊密跟隨理論線性擴展上限,展現出卓越的大規模分布式訓練可擴展性。這意味著企業能以更低算力成本、更短訓練周期完成模型迭代,實現從實驗到落地的高效轉化。

架構揭秘
從「大腦」到「小腦」的智能耦合
剛才提到,LingBot-VLA 在模型架構、數據效率、訓練效率等方面都經得起考驗,那么,螞蟻靈波是怎么做到的呢?在技術報告中,他們透露了一些細節。
首先,在架構層面,LingBot-VLA 沒有從零開始,而是選擇了一個強大的預訓練視覺語言模型(Qwen2.5- VL)作為理解世界的「大腦」,然后為其配上一個專門負責生成機器人動作的「動作專家」。兩者并非簡單拼接,而是通過一種名為Mixture-of-Transformers (MoT)的架構有機結合:視覺、語言和動作數據各自通過獨立的處理通路,又在每一層通過共享的注意力機制進行交互。這樣既保證了視覺語義知識能持續指導動作生成,又避免了不同模態信息間的相互干擾。

在動作生成上,模型采用了Flow Matching方法來建模連續、平滑的動作軌跡,這有助于提升復雜操作的控制穩定性。
對于機器人操作至關重要的空間感知能力,LingBot-VLA 采用了一種基于視覺蒸餾的深度信息融合方法。其核心在于:模型并未直接將深度圖作為原始輸入,而是通過一套可學習的查詢(Learnable Queries)機制,使其視覺語言主干(VLM)提取的特征,與專用深度模型 LingBot-Depth 所生成的空間表征進行對齊。這讓模型在推理時無需深度圖輸入,就能具備對三維幾何關系的隱式理解,從而實現了在抓取、放置等任務中精度的大幅提升。具體效果如視頻所示。

https://mp.weixin.qq.com/s/o0WKZi-JFYd8ZDHV6_5Xfg?click_id=26
在訓練效率方面,研發團隊還對其訓練代碼庫進行了系統級優化。在分布式策略上,采用經過改進的 FSDP 策略,在內存占用與通信開銷間取得了最佳平衡;在算子層面,利用 FlexAttention 和算子融合等技術,大幅提升了核心計算效率。最終,其訓練吞吐量達到了每 GPU 每秒 261 個樣本,相比主流開源代碼庫有 1.5 至 2.8 倍的加速,且擴展性極佳,能隨著 GPU 數量增加近乎線性地提升訓練速度。
LingBot-VLA——
開源具身基座模型新起點
總體而言,無論在模型泛化能力還是訓練效率方面,LingBot-VLA 都已樹立起一個新的行業標桿。然而,其真正的深遠意義,不止于一次性能的超越,更在于它為「通過擴展真實數據實現更強泛化」提供了首個扎實的實證。
螞蟻靈波在技術報告中首次系統性地揭示了 VLA 模型在真實機器人數據上的 Scaling Law:隨著預訓練數據規模從 3000 小時逐步擴展至 20000 小時,模型在下游任務的成功率獲得了持續且顯著的提升。尤為關鍵的是,即使達到 20000 小時這一量級,模型性能曲線仍未顯示飽和跡象。這一發現為行業點亮了一座燈塔,用數據證實了「大力出奇跡」的路徑在真實機器人學習中依然有效,為后續的大規模數據開發指明了可預期的回報。

更進一步看,這類以真實交互數據為核心、兼顧規模與效率的成功實踐,也為 VLA 模型未來與世界模型的深度融合奠定了現實基礎
不過,所有模型在 GM-100 上平均成功率都未超過 20% 的現實也在提醒我們,具身模型 —— 尤其是開源具身模型 —— 距離真正的跨本體、跨場景泛化還有很長的路要走。接下來,相關從業者可以在 LingBot-VLA 的基礎上繼續前進,而螞蟻靈波的全鏈路開源(模型權重、代碼、后訓練工具鏈全部開源)也為這種持續迭代提供了土壤。
但如果把它放到更長周期里看,LingBot-VLA 可能還有另一層意義 —— 它也可以被理解為螞蟻 AGI 版圖里一次面向「真實世界交互」的落子:在基礎大模型(百靈)與通用助手(靈光)等「通用智能」能力之外,通過具身智能把模型帶入可驗證、可復現的物理世界閉環。
這也解釋了它為什么選擇以開源方式發布,并同步建設 InclusionAI 這樣的開源社區與技術體系:用更開放的協作與復現機制擴大驗證面,讓具身智能的迭代速度更接近 AGI 需要的「規模化試錯」。
標桿的意義,在于被超越,更在于指明方向。LingBot-VLA 的發布,或許正是這樣一個新方向的開始。
特別聲明:以上內容(如有圖片或視頻亦包括在內)為自媒體平臺“網易號”用戶上傳并發布,本平臺僅提供信息存儲服務。
Notice: The content above (including the pictures and videos if any) is uploaded and posted by a user of NetEase Hao, which is a social media platform and only provides information storage services.








































































